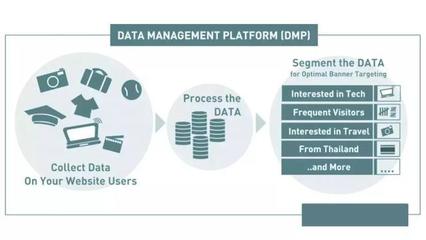
在当今信息爆炸的时代,数据已成为驱动社会进步和企业决策的核心要素。面对海量、多样、高速产生的数据,传统的数据处理技术已难以应对,大数据技术应运而生。在众多大数据处理框架中,Hadoop以其高可靠性、高扩展性和低成本等优势,成为了事实上的行业标准。本文将深入探讨Hadoop数据处理的核心概念、技术架构、典型流程及其应用价值。
一、Hadoop 概述:分布式系统基石
Hadoop是一个开源的分布式计算框架,由Apache基金会维护。其核心设计灵感来源于Google的MapReduce编程模型和Google File System(GFS)。Hadoop旨在将海量数据集的存储和处理任务,分散到成百上千台廉价的商用服务器集群上,从而实现并行、高效的计算。其核心优势在于:
- 高可靠性:数据在集群中被多副本存储,即使部分硬件发生故障,系统也能自动恢复,保证数据不丢失。
- 高扩展性:可以通过简单地增加节点来线性扩展集群的存储和计算能力。
- 高容错性:任务执行失败后,能自动重新调度到其他节点完成。
- 低成本:构建在廉价的商用硬件之上,降低了大数据处理的入门门槛。
二、Hadoop 核心组件:一个协同工作的生态系统
Hadoop生态系统主要由两大核心组件构成,它们共同支撑起数据处理的全流程:
- Hadoop Distributed File System (HDFS):分布式文件系统。
- 职责:负责数据的存储。它将大文件(如TB、PB级)切割成固定大小的数据块(默认为128MB或256MB),并将这些数据块及其冗余副本分布式地存储在整个集群的多个节点上。
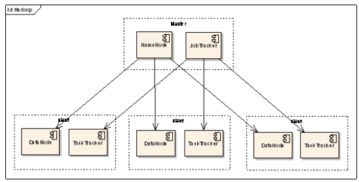
- 架构:采用主从(Master/Slave)架构。
- NameNode:主节点,负责管理文件系统的命名空间(如目录树、文件元数据)以及数据块到DataNode的映射关系。它是整个HDFS的大脑。
- DataNode:从节点,负责存储实际的数据块,并执行数据块的读写操作。
- Hadoop MapReduce:分布式计算框架。
- 职责:负责数据的计算。它将计算任务抽象为两个主要阶段:Map(映射)和Reduce(归约)。
- 编程模型:
- Map阶段:将输入数据分割成独立的片段,由多个Map任务并行处理,输出一系列中间键值对(key-value pairs)。其核心思想是“分而治之”。
- Shuffle & Sort阶段:系统自动将Map输出的中间结果,按照Key进行排序、分区,并传输到对应的Reduce节点。这是连接Map和Reduce的关键环节。
- Reduce阶段:接收属于同一个Key的所有中间值,进行聚合、汇总或其他计算,最终产生输出结果。
- 架构:同样采用主从架构。
- ResourceManager:主节点,负责整个集群的资源管理和作业调度。
- NodeManager:从节点,负责管理单个节点上的资源和任务执行。
三、Hadoop 数据处理典型流程
一个完整的Hadoop数据处理作业通常遵循以下步骤:
- 数据输入:原始数据(如日志文件、数据库导出文件)被上传或写入HDFS。HDFS会自动将其分块并分布式存储。
- 作业提交:用户编写MapReduce程序(Java、Python等),定义好Map和Reduce函数逻辑,然后将作业提交给ResourceManager。
- 任务调度与执行:ResourceManager根据数据本地性(将计算任务调度到存储有所需数据块的节点上,以减少网络传输)原则,在集群的NodeManager上启动Map任务。每个Map任务处理一个数据块。
- Map阶段:Map任务读取其分配的数据块,逐行处理,执行用户定义的Map函数,生成中间键值对。
- Shuffle与Sort:Map任务的输出被写入本地磁盘,然后根据Key进行分区和排序,通过网络传输到将要执行Reduce任务的节点。
- Reduce阶段:Reduce任务拉取所有Map任务中属于自己分区的、已排序的中间数据,执行用户定义的Reduce函数,进行最终的聚合计算。
- 结果输出:Reduce任务的结果被写入HDFS,作为最终输出文件。
四、超越 MapReduce:YARN 与现代生态
早期的Hadoop 1.x版本将资源管理与作业调度紧密耦合在MapReduce框架内,限制了集群的灵活性和对其他计算模型的支持。Hadoop 2.x引入了YARN(Yet Another Resource Negotiator),将资源管理功能从MapReduce中剥离出来,成为一个独立的通用资源管理层。
- YARN的作用:它使得Hadoop集群可以同时运行多种计算框架,如MapReduce、Spark(内存计算)、Flink(流处理)、Tez(DAG计算)等,真正将Hadoop从一个单一的计算系统升级为一个大数据操作系统。
五、Hadoop 数据处理的应用与挑战
应用场景:
海量日志分析:分析网站点击流、服务器日志,进行用户行为分析、异常检测。
推荐系统:基于用户历史行为数据,进行协同过滤等大规模计算,生成个性化推荐。
数据仓库:构建企业级数据仓库(如Apache Hive),进行复杂的ETL(抽取、转换、加载)和离线批处理分析。
文本挖掘与自然语言处理:处理大规模文本语料库,进行词频统计、情感分析等。
面临的挑战:
实时性不足:经典的MapReduce基于磁盘I/O,适合离线批处理,但对实时或近实时查询响应较慢。
编程复杂度:直接编写MapReduce程序相对繁琐,需要关注底层细节。
* 生态系统复杂性:Hadoop生态包含众多组件(如Hive, HBase, Spark等),学习、选型和运维成本较高。
###
Hadoop作为大数据处理的奠基者,其分布式存储(HDFS)和批处理计算(MapReduce/YARN)思想深刻地影响了整个行业的发展。尽管在面对实时流计算等场景时,出现了Spark、Flink等更高效的计算引擎,但Hadoop的核心存储系统HDFS和资源管理框架YARN,仍然是许多大型企业大数据平台的基石。理解Hadoop数据处理原理,是踏入大数据领域、构建稳定可靠的数据处理管线不可或缺的关键一步。