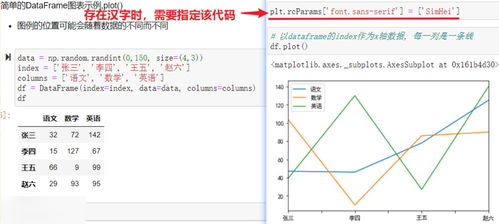
在数据科学和分析领域,数据处理是至关重要的一环。Python的Pandas库凭借其强大且灵活的数据结构,已成为数据处理与分析的首选工具。本文将重点介绍三种核心的Pandas数据处理方法,并简要探讨如何利用这些处理结果进行基础绘图,以实现数据的可视化洞察。
一、核心数据处理方法
1. 数据清洗与准备
处理数据的第一步往往是清洗。Pandas提供了丰富的方法来处理缺失值、重复数据以及异常值。
- 处理缺失值:常用方法包括
dropna()删除含有缺失值的行或列,以及fillna()用特定值(如均值、中位数或前向/后向填充)来填补缺失值。
- 处理重复数据:使用
duplicated()检查重复行,并用drop_duplicates()将其删除。
- 数据类型转换:使用
astype()方法可以改变某一列的数据类型,例如将字符串转换为数值,这对后续的数学运算和绘图至关重要。
2. 数据筛选、排序与分组
从数据集中提取有用信息是核心任务。
- 筛选:可以使用布尔索引(例如
df[df['列名'] > 100])或query()方法来高效地筛选出满足条件的行。
- 排序:
sort_values()方法可以根据一列或多列的值对数据进行升序或降序排列,便于观察极值和趋势。
- 分组聚合:
groupby()是Pandas最强大的功能之一。它可以按照某个或某几个键将数据分组,然后对每个组应用聚合函数(如sum(),mean(),count())。例如,df.groupby('类别')['销售额'].sum()可以快速计算每个类别的总销售额。
3. 数据变形与合并
在实际项目中,数据通常来自多个源头,需要整合。
- 数据合并:
concat()用于沿轴(行或列)拼接多个DataFrame。merge()或join()则类似于SQL的连接操作,基于一个或多个键将不同的DataFrame横向合并。
- 数据透视:
pivot_table()函数可以创建数据透视表,它能对数据进行多维度汇总,是进行高层次分析的利器。
- 应用函数:
apply()和map()方法允许对Series或DataFrame的元素、行或列应用自定义函数,极大地扩展了数据处理能力。
二、数据处理结果的绘图实践
数据处理后,可视化是呈现结论的关键。Pandas内置了基于Matplotlib的绘图接口,使得绘图变得异常简单。通常,数据处理的结果(如聚合后的Series或DataFrame)可以直接用于绘图。
1. 基础绘图流程
在完成数据处理(如分组聚合)后,可以直接在结果上调用绘图方法。例如:
`python
# 假设已有一个经过处理的DataFrame df_summary
df_summary.plot(kind='bar') # 绘制条形图
plt.title('各产品类别销售额汇总')
plt.xlabel('产品类别')
plt.ylabel('销售额')
plt.show()
`
- 常用图表类型与数据处理结果对应
- 折线图 (
kind='line'): 非常适合展示时间序列数据(如按月份聚合后的销售额趋势)。
- 条形图/柱状图 (
kind='bar'): 用于比较不同类别(如分组聚合后的各个类别)的数值大小。
- 直方图 (
kind='hist'): 用于查看单个数值变量的分布情况(如客户年龄的分布)。
- 箱线图 (
kind='box'): 用于识别数据中的异常值和分布范围(如查看各区域销售额的离散情况)。
- 散点图 (
kind='scatter'): 用于观察两个数值变量之间的关系(通常在数据清洗和筛选后,选取相关列进行绘制)。
结论
数据处理与绘图是一个紧密相连的流程。高效的数据处理(清洗、筛选、聚合)为有意义的可视化奠定了坚实的基础。通过Pandas强大的数据处理能力,结合其简洁的绘图API,我们可以快速地从原始数据中提炼出有价值的信息,并通过直观的图表呈现出来,从而驱动决策和洞察。掌握数据处理的核心技能,是解锁数据可视化全部潜力的第一步。