在当今大数据时代,Hadoop生态系统已成为企业从海量数据中提取价值的核心工具。它如同一座桥梁,将原始数据的浩瀚海洋转化为可操作的智慧金矿。本文将带您探索Hadoop生态系统的关键组成部分,揭示它们如何协同工作,实现高效的数据处理旅程。
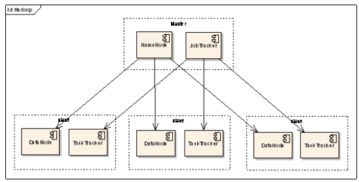
Hadoop的核心是HDFS(Hadoop分布式文件系统)。它作为数据存储的基石,能够将大规模数据集分布式存储在廉价的硬件集群上。HDFS的设计允许数据的高容错性和高吞吐量访问,为整个生态系统提供了可靠的数据基础。想象一下,数据海洋中的每一滴水都被安全地存储和复制,确保不会因单点故障而丢失。
接下来是数据处理的核心引擎:MapReduce。这是一种编程模型,用于并行处理大规模数据集。MapReduce将复杂的任务分解为简单的映射(Map)和归约(Reduce)阶段,使得在成百上千台机器上并行执行成为可能。通过MapReduce,原始数据被逐步清洗、转换和聚合,如同从矿石中提炼黄金的过程。
Hadoop生态系统远不止于此。YARN(Yet Another Resource Negotiator)作为资源管理器,负责集群资源的分配和调度。它确保了多个应用程序可以高效共享集群资源,避免了资源冲突,提升了整体利用率。YARN的引入使得Hadoop从单一的数据处理平台演变为一个多任务操作系统。
在数据存储和处理的基础上,Hive和Pig等工具提供了更高级的数据操作接口。Hive允许用户使用类似SQL的查询语言(HiveQL)来处理数据,降低了大数据分析的门槛。而Pig则通过其脚本语言Pig Latin,简化了复杂数据流的设计。这些工具让数据分析师能够更专注于业务逻辑,而不是底层代码。
对于实时数据处理,Hadoop生态系统提供了Apache Spark。Spark以其内存计算能力著称,能够比MapReduce快数倍处理数据。它支持流处理、机器学习和图计算等多种应用,是构建实时分析应用的首选。HBase作为分布式NoSQL数据库,提供了低延迟的随机读写能力,适用于需要快速访问的场景。
数据集成和治理也是关键环节。Apache Sqoop和Flume负责数据的导入导出,Sqoop专用于与关系数据库交互,而Flume则处理日志数据的实时收集。同时,Apache Atlas等工具提供了数据血缘和治理功能,确保数据在整个生命周期中的可追溯性和合规性。
机器学习库如Mahout和MLlib(Spark的机器学习库)赋予了Hadoop生态系统智能分析的能力。它们支持分类、聚类、推荐等算法,帮助企业从数据中挖掘深层洞察,真正实现从数据到智慧的转化。
Hadoop生态系统通过其多样化的组件,构建了一条从数据采集、存储、处理到分析的完整链条。它不仅仅是技术工具的组合,更是一场将杂乱数据转化为宝贵智慧的奇妙旅程。随着技术的演进,Hadoop继续引领着大数据处理的未来,帮助组织在数据海洋中淘金,释放无限商业价值。